
Project 3: Are You a Good Witch or a Bad Witch?
Due by: Friday, November 7, 2025 at 11:59 p.m.
Introduction
What if you could teach a computer to know the difference between good and evil? A tall order, no doubt. What about the difference between positive and negative? That's much more reasonable. Maybe we could do so by showing the computer many different examples of positive and negative statements. Where would such things come from? Movie reviews, of course! People love movies. People hate movies. And, most importantly, people are paid to write reviews for movies.
If we could analyze the words from a large number of movie reviews, knowing the rating given to the film (0-4), we could then examine new reviews (or any random phrase) and make a guess whether it was a positive review or a negative one. This use of a computer to determine the feeling behind text is called sentiment analysis. Sentiment analysis has been used to examine Facebook posts and Twitter feeds to uncover everything from cyber-bullying to political party affiliation. The sentiment analysis we're going to do uses a very simple approach. We will keep track of all the words found in every review. The score for the word will be an average of the scores of all the reviews that word appears in. When analyzing a new phrase, we can simply average the scores of each of the words in the phrase together. In the range 0-4, the score 2 is right in the middle. Thus, scores above 2 will be considered positive, and scores below 2 will be considered negative.
Overview
Even this simple algorithm has a lot of details to flesh out. Since this is a data structures course, a key feature is that storing and retrieving word scores must be efficient. Thus, the words and their scores should be kept in a balanced binary search tree, specifically a red-black tree. Here are the steps needed to finish the project.
- Parsing the Words
Open a document containing reviews and parse the words out of the text. - Storing the Words
Store the words in a data structure and keep a count of total rating as well as the number of ratings. By keeping both pieces of information, an average score can be produced at any time. - Outputing Word Statistics
Once you have stored all the words, create a file that lists the scores for each word. This file will be useful for testing. - Reading New Phrases
Your code will need to prompt the reader for a phrase to analyze, over and over. Parsing the words out of this phrase will be very similar to the parsing done before. - Rating Each New Phrase
Rate each new phrase as positive, negative, neutral, or no sentiment.
Parsing the Words
Which Files?
Before you can parse the words out of the files, you need to know what files you want to open, and then open them. Your main() method should be in a class called SentimentAnalyzer. To make the sentiment analyzer more accurate, we want to ignore certain very common words like the and of. In sentiment analysis, these words are called stop words. First, prompt the user for the name of file containing stop words. This file is guaranteed to consist of legal words, listed one per line, requiring no special parsing.
Once you have read the stop word file, you should prompt the user for a review file, containing all of the reviews you're going to use for analysis. Sample output for your program follows. As in the past, green represents user input.
Enter a stop word file: stop.txt Enter a review file: reviews.txt
In this example, stop.txt is the name of the stop word file, and reviews.txt is the name of the file containing reviews. Do not hardcode the names of these input files! If either the stop word or the review file cannot be opened (perhaps it doesn't exist), your program should print an appropriate error message to standard output and prompt the use to enter another file name.
Parsing
No special parsing is needed for the stop word file. Every word is legal and will appear on a line by itself. However, the review file is more complicated. Each line of the review file contains a review. Each review begins with an integer between 0 and 4, inclusive, followed by white space. The rest of the line contains the text of the review. You will need to parse the review text into individual words. You will need to keep track of the total score given to each word as well as how many times each word appears and store this data in your WordTable structure which will be explained in detail in the Storing the Words section. You should ignore capitalization differences between words and store each word in lower case. When parsing words, you should consider a word to be a set of characters which start and end with a letter (A-Z and a-z). A word cannot contain any characters other than a letter, an apostrophe ('), or a hyphen (-). Examples of how some words should be parsed are shown below.
- point2Point
- 2 "point"
- I'm excited!!!!!!!
- 1 "i'm"
- 1 "excited"
- x-axis
- 1 "x-axis"
- lions,and tigers
- 1 "lions"
- 1 "and"
- 1 "tigers"
- but...I don't understand -isms***
- 1 "but"
- 1 "i"
- 1 "don't"
- 1 "understand"
- 1 "isms"
A sample review file for you to test with can be found here.
There are several different ways to achieve the parsing you need to do for this project. As you know from the previous project, parsing can be one of the more difficult parts of a project, and you may need to examine input character by character in order to do it properly.
Storing the Words
Data Structures
So, you need to store these words somehow. You are required to store them in a kind of overblown hash table. A hash table is a way of organizing information to make a look-up, i.e., to see if a value already exists, efficient. Usually a hash table involves an array. Adding a piece of data to a hash table involves using a hash function to decide which element of the array to put the piece of data into.
In our case, let's keep things simple. You will need to create a class called WordTable that contains an array with 26 elements in it, one for every letter of the alphabet. Every legal word must start with some letter between 'a' and 'z'. Somehow you want to store a word in the element of the array which corresponds to the letter it starts with. How will you do that? Every element of the array will not be a reference to a String, but rather to a red-black tree of String values. Below is a graphic illustrating what the data structure might look like.
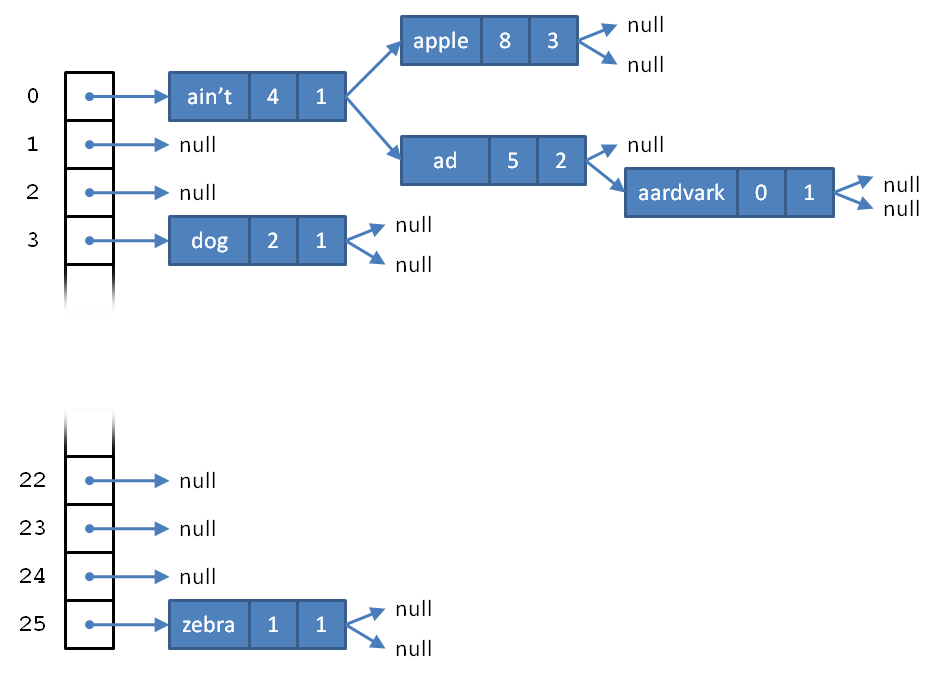
Naturally, this means that you must implement a WordTree class to hold the data for each element of the array.
First, you should open the stop word file and add every word in it into a WordTable. Then, you should parse every word from the reviews in the review file and add those words to a different WordTable object. However, you should not add a word into the review WordTable if that word is contained in the stop words WordTable. In other words, the whole purpose of storing all of the stop words into a WordTable is so that you can efficiently check to see if a review word is a stop word or not. If it is a stop word, there's no reason to add it to the WordTable that stores review words.
Details
The WordTable class is not very complicated. It holds an array of 26 WordTree objects and methods to interact with those WordTree objects. You may choose which methods to implement for WordTable, but I recommend the following.
public void add(String word, int score)
Addswordto the appropriateWordTree, with the givenscore.public double getScore(String word)
Gets the average score of a word from the appropriateWordTree.public boolean contains(String word)
Asks the appropriateWordTreeif it containsword.public void print(PrintWriter out)
Loops through all 26WordTreeobjects and print out their data.
Each node inside the WordTree should have the following form:
private static class Node {
public String word;
public int score;
public int count;
public boolean black;
public Node left;
public Node right;
}
The score field keeps track of the total of all review scores that this word appears in. The count keeps track of the total number of times that this word appears in any reviews. Dividing the two numbers gives the average score for a word. Note that it is necessary to keep both quantities so that additional review scores can be added later.
The black field states whether the given node is black (true) or red (false).
Although you are free to change them and implement additional methods as needed, class WordTree should implement methods similar to the following. Note that these public, non-recursive methods will depend on private, static, recursive methods.
public void add(String word, int score)
Adds aStringto aWordTreewith a givenscore. Ifwordis already contained in theWordTree, this method should add the suppliedscoreto thescoreof the givenNodeand increment itscount. Otherwise, this method should insert a newNodeat the appropriate place in theWordTree, with the suppliedscoreand acountof 1, rebalancing and recoloring the tree if necessary to maintain the red-black properties.public boolean contains(String word)
Returnstrueifwordhas already been added to theWordTreeandfalseotherwise.public double getScore(String word)
Searches forwordin the tree. If found, it will return the floating-point quotient of the correspondingNode'sscoreandcount. If the word is not found, it will return2.0, a neutral score.public void print( PrintWriter out )
This method prints out each word in theWordTreein alphabetical order, followed by a tab, followed by its total score, followed by a tab, followed by its count, followed by a newline. It makes sense to adapt an inorder traversal to this task.
You may implement any other utility methods you find useful, including recursive helper methods to implement the methods given above.
Outputing Word Statistics
In order to check your work, create a file to hold statistics for the words in your reviews. The name of this file should be the same as the review file, with .words appended. This task is precisely what the print() methods in WordTable and WordTree are designed for.
This file should contain all of the words in all of the reviews (excluding stop words) listed in alphabetical order. Each word should appear on its own line with its total rating and total count following and tabs separating these values. The file reviews.txt.words is sample output for the review file reviews.txt used with stop word file stop.txt.
Reading New Phrases
Once the review words and stop words are loaded into the tables, the program is ready to read new phrases for sentiment analysis. The program should ask the user if he or she wants to analyze a phrase (yes or no). If yes, the program should read in the next line of text, parsing it as before to extract all the words, in lower case.
The program should allow the user to enter as many phrases as the user wishes. Each time, the program should ask if the user wants to analyze a phrase. If the answer is yes, analyze the phrase and prompt again. If the answer is no, the program should quit. If the answer is something else, prompt the user again.
Rating Each New Phrase
As each word in a new phrase is parsed, its score should be looked up. By adding up those scores and dividing by the total number of words, the phrase can be given a rating.
Note that words in the new phrase should be checked to see if they are stop words. A stop word does not contribute to the score of a phrase, and it does not increase the count of words found. Thus, if a phrase consists only of stop words, the count of real words in the phrase is 0, and your program should output: Your phrase contained no words that affect sentiment.
Otherwise, print out the score. There will be three possibilities. The phrase could have a sentiment greater than 2.0, meaning that the phrase was positive. In that case output: Your phrase was positive. The phrase could have a sentiment less than 2.0, meaning that the phrase was negative. In that case output: Your phrase was negative. Finally, it could have a phrase exactly equal to 2.0, meaning that the phrase was perfectly neutral or contained only words that did not appear in any reviews. In that case output: Your phrase was perfectly neutral.
Below is sample input and output for a complete execution of the program. Green represents user input.
Enter a stop word file: stop.txt Enter a review file: reviews.txt Word statistics written to file reviews.txt.words Would you like to analyze a phrase? (yes/no) yes Enter phrase: I hate myself, and I want to die. Score: 1.673 Your phrase was negative. Would you like to analyze a phrase? (yes/no) yes Enter phrase: The time to be happy is now. The place to be happy is here. Score: 2.245 Your phrase was positive. Would you like to analyze a phrase? (yes/no) yes Enter phrase: Zimbabwe. Score: 2.000 Your phrase was perfectly neutral. Would you like to analyze a phrase? (yes/no) yes Enter phrase: The of is me. Your phrase contained no words that affect sentiment. Would you like to analyze a phrase? (yes/no) no
Recap
You need to do five things.
- Parsing the Words
Read words from a stop word list and from a file containing reviews. The reviews will require work to parse out only words. - Storing the Words
Store word information from each file, using twoWordTableobjects. - Outputing Word Statistics
Create an output file listing the statistics (total rating and count) for each (non-stop) word in the reviews. - Reading New Phrases
Repeatedly, prompt the user for phrases. - Rating Each New Phrase
Rate each new phrase as positive, negative, neutral, or no sentiment.
Hints
- Start early. I can prove this to you:
- Because of simple laws of space and time, one can only start early, on time, or late.
- Starting late is wrong.
- It always takes longer than you think.
- If it always takes longer than you think, starting on time is starting late.
- By #2, starting late is wrong.
- Thus, starting early is the only way. QED
- Think carefully about how you are going to implement
WordTree. I have suggested some methods, but you are free to change them and write other methods as needed. - Think before you code. I have to write these programs first before I give them to you. I'm lazy and don't like having to code long projects. For example, if you are writing 26
ifstatements, you are doing something wrong. Most problems I give have fairly straight-forward implementations in code. If you think your approach is too convoluted, get a sanity check. 1 minute of design = 10 minutes of coding = 100 minutes of debugging. - Work incrementally and test often. You can test the program with just the
WordTreeclass. (You don't have to have a hash table ofWordTreereferences for the code to work.) Likewise, implement theWordTreeclass as an unbalanced binary search tree first. Once it's working, change it to a red-black tree (which will only change theadd()method).
Submit
Zip up all the .java files you use to solve this problem from your src directory and upload this zip file to Brightspace.
All work must be submitted by Friday, November 7, 2025 at 11:59 p.m. unless you are going to use a grace day.
Only the team leader should turn in the final program. I must be able to compile your program with the command javac SentimentAnalyzer.java and run with the command java SentimentAnalyzer.
All work must be done within assigned teams. You may discuss general concepts with your classmates, but it is never acceptable for you to look at another team's code. Please refer to the course policies if you have any questions about academic integrity. If you have trouble with the assignment, I am always available for assistance.
Grading
Your grade will be determined by the following categories:
| Category | Weight |
|---|---|
| Parsing words correctly. | 20% |
Correct implementation of WordTable and WordTree. |
20% |
| Outputing the word statistics in the correct format in a correctly named file. | 15% |
| Reading and parsing new phrases. | 10% |
| Rating each new phrase and giving correctly formatted output. | 15% |
| Red-black tree implementation. (Note: You can choose to implement the project with an unbalanced tree and forfeit these points. In fact, it is recommended that you first get the program working with an unbalanced binary search tree and then upgrade it a red-black tree.) | 10% |
| Style and comments | 10% |
Note: Submissions which do not compile will automatically score zero points.
Under no circumstances should any member of one group look at the code written by another group. Tools will be used to detect code similarity automatically.
