C SC 340 Lecture 7: Deadlock
[ previous
| schedule
| next ]
additional resource: Modern Operating Systems (2nd Ed), Tanenbaum,
Prentice Hall, 2001.
Note: All the problems, solutions, and algorithms in this lecture apply equally
to both processes and threads.
What is deadlock?
Here are some video examples:
Italian Traffic Jam (2:12)
and Dead Lock (3:17)
and Political Deadlock at York U (3:49)
Follow the time sequence in this scenario:
- System resources Q and R can only be used by one process at a time
- Process A requests and gets resource Q and holds it
- Process B requests and gets resource R and holds it
- Process A requests resource R, and blocks because B is holding it
- Process B requests resource Q, and blocks because A is holding it
- Both A and B are deadlocked. Each is blocked for a resource that
the other holds.
This situation can be very easy to fall into and difficult to prevent. For instance
in Java, the processes can be threads and the resources can be objects. It is
the Java programmer's responsibility to prevent deadlock, because JVM
does not try to detect or recover from deadlock.
Tanenbaum's definition is a good one: A set of processes is deadlocked if each process
in the set is waiting for an event that only another process in the set can cause.
What conditions cause deadlock?
Four conditions must simultaneously exist for deadlock to occur:
- mutual exclusion. One or more of the resources must require mutually
exclusive access (e.g. printer). A requesting process blocks if resource is busy.
- hold-and-wait. One of more of the processes must hold at least one
resource while blocked for another.
- non-preemptive. Process releases resource only voluntarily.
- circular wait. Must have a circular chain of processes, each of which
is waiting for resource held by the next chain member.
We'll look at an example, and identify how all four conditions are met.
How do OSs approach deadlocks?
Most OSs, including Windows, Unix and Linux, apply the ostrich algorithm
(term attributed to Tanenbaum)....they ignore it and hope it doesn't happen.
This approach is justifiable, based on risk analysis. If the costs outweigh the
benefits, there is no reason to do it. We'll see shortly the costs are high. For
general purpose OSs, the benefits are low. Responsibility shifts to those who implement
software development tools (e.g. Oracle) as well as the programmers who use them.
If OS designers decide to tackle deadlocks, the major approaches are:
- prevention. Deny one or more of the four necessary conditions.
- avoidance. Allow the conditions but dynamically analyze the situation
to detect and deny requests that could lead to deadlock.
- detection and recovery. Allow deadlocks to occur, then detect and
recover from them.
How can deadlocks be detected?
The last two approaches both require the OS to "know" what a deadlock "looks
like." Deadlocks can be reasonably modeled using a system-wide Resource Allocation
Graph (RAG).
Note: I'll restrict the system to have only nonsharable resources of which there
is a single instance (e.g. a system with one printer and one tape drive). It will
illustrate the concepts with a minimum of details. There are algorithms that do not
require these restrictions.
A resource allocation actually includes both allocations and requests. A graph
has the following components:
- Processes Pi, drawn as circles
.
- Resources Ri, drawn as squares
.
- Requests, drawn as unlabeled directed edge from a process to a resource.
- Allocations, drawn as unlabeled directed edge from a resource to a process.
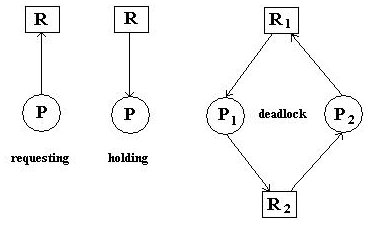
"Draw" a graph representing the global system state, where Pi are all
system processes and Ri are all the system resource. "Draw" the current
allocations and requests.
The system contains a deadlock if the graph contains any cycles. All processes
in a cycle are said to be deadlocked. The figure above shows two processes and
two resources, but the cycle could involve many more than two processes.
The graph is obviously not really drawn, but appropriate graph data structures and algorithms
can easily be developed to detect deadlocks or potential deadlocks.
Deadlock Prevention
As state above, this requires denying one or more of the four conditions.
- denying mutual exclusion. Cannot be done for intrinsically nonsharable devices (e.g. printers). So this
is not an easy avenue toward prevention.
- denying hold-and-wait. Two approaches: either require a process to
release all held resources before the next request, or require it to request
all resources before execution begins. The former restricts process structure;
the latter reduces system performance.
- denying non-preemption. Allow OS to preemptively release resources
held by a process when it requests a non-available resource. The process cannot
run again until it is able to acquire both the preemptively-released resources
and the one it was requesting. This is not practical for all resource types (e.g. printers).
- denying circular wait. The classic approach is to assign a total ordering
on all the resources, then allow a process to request resources only in increasing order. Or upon
request of a resource, force it to release higher-numbered resources.
None sounds very appealing, but for certain systems, such as real-time embedded systems, they
are feasible. Remember, you only need to deny one of the four.
Deadlock Avoidance
The strategy here is for the OS to deny a resource request that could lead to deadlock.
There are a number of strategies and algorithms for doing this. They focus on keeping
the system in a safe state: a state in there is at least one deadlock-free
scheduling sequence to completion even if all processes request all their resources at once.
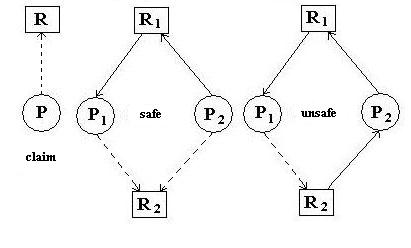
One is to maintain a RAG supplemented with an additional edge type:
the claim edge. A claim edge represents a future process request
for a resource. If these are added to the RAG, then a request can be evaluated for
its safeness: if allocation would result in a cycle, it should not be granted. Example
below for P2 claim on R2 and what would occur were it allocated.
Dijkstra's Banker's algorithm could be employed. A banker (the OS)
has several customers (processes) which ask for loans (resources) from their
lines of credit (maximum resources required for completion). Once a customer
has depleted its line of credit, it pays off the entire loan (releases all resources).
The combined lines of credit are greater than the amount of money on hand in
the bank (available resources). The banker can grant a loan request only if
the remaining money on hand is enough to cover all the possible future loan
requests in some sequence. This is illustrated below in an example
for one resource type of which multiple units are available.
|
|
|
|
|
start: 8 units free
|
safe: 4 units free
|
unsafe: 3 units free
|
This diagram shows three system snapshots:
- left: System starts with 8 units of a resource and three new processes A, B, C.
- center: system is in a safe state: if C requests its remaining
4 units then releases all 6, then either A or B can request its remaining 5 units then
release all and the other can request its remaining 5 and get them all.
- right: system is in an unsafe state: what has happened instead is that
B has requested and been granted 1 unit. If any of the processes then makes its
maximum request the system is deadlocked.
Deadlock Detection
Pretty much covered above: Build/maintain a RAG and look for cycles.
Deadlock Recovery
Recovery methods are unsavory and fall into two categories:
- terminate as many deadlocked
processes as are necessary to break the deadlock
- preemptively release resources
from processes until the deadlock is resolved.
The major policy design is which process(es) to terminate or preempt. This decision
is based on process properties (which are stored in PCB and OS data structures).
One possibility is rollback. "Undo" the actions of a process until
it reaches pre-deadlock state. Then resume it later (after potential for deadlock
is past) from that state.
[ C
SC 340 | Peter
Sanderson | Math Sciences server
| Math Sciences home page
| Otterbein ]
Last updated:
Peter Sanderson (PSanderson@otterbein.edu)