SEL3350: COMPUTATIONAL LINGUISTICSDr. Hermann Moisl, senior lecturer in linguistics at Newcastle UniversityWay-back Machine: October 12, 2014Lecture 5 Theory Phrase Structure Grammars (continued) We are now in a position to formalise the ideas about phrase structure grammars we looked at last time. This formalisation begins the study of formal language theory. Definition: phrase structure grammar A phrase structure grammar (henceforth PSG) has four components:
a = xNz b = xyz
Components 1-3 of this definition should be clear enough, but 4, being stilted, requires some comment. It says that all production must have the form a--> b. What do a and b consist of? Well, a must have at least one nonterminal symbol in it; it may also have some arbitrary string of terminals and/or nonterminals in front of it, and may also have some arbitrary string of terminals and/or nonterminals following it, but need not. In other words, a is some string of terminals and/or nonterminals, with the constraint that at least one of the symbols must be a nonterminal. For b there is no constraint at all: it can consist of any finite string of terminals and/or nonterminals, including the empty string --that is, the right side of the production may have nothing at all.
Types of phrase structure grammar Phrase structure grammars can be subcategorised by stipulating various degrees of restriction on the forms which the productions can take. There are four standard categories; they constitute the Chomsky Hierarchy. Type 0: unrestricted grammars This type of PSG is identical to the general type of PSG just discussed. Only one further point about this class of grammars has to be made here. Implicit in the foregoing definition was that the right side of a production can be null in cases where x,y,z are all empty strings. When used to rewrite a sentential form, such a production causes some nonterminal in the current sentential form to be rewritten as the null string, with the effect that the sentential form contracts. The property of allowing the sentential form to contract is unique to type 0 PSGs, and, apparently paradoxically, makes them so powerful in terms of the languages they can generate that linguists find them useless.
Type 1: Context sensitive grammars A context sensitive grammar is a PSG in which all the productions have the form xNz --> xyz where:
Such grammars are called 'context sensitive' because N can be rewritten by y only when it is in the context of x and z --that is, when, in the current sentential form, the string x precedes N and the string y follows it.
Type 2: Context free grammars A context free grammar is a PSG in which all the productions have the form xNz --> xyz where:
Note the difference between this specification and the one for context sensitive grammars. In the latter, the strings preceding and following the terminal on the left side were arbitrary: they could be composed of terminals and/or nonterminals, and one or both of them could be null. In a context free grammar, however, they must be null. As a consequence, the left side of a production in a context free grammar always consists of exactly one nonterminal or S. This is why such grammars are called 'context-free'. The N on the left side of the production can be rewritten by the string y on the right regardless of the context in which N finds itself in the current sentential form; it is independent of its context.
Type 3: Regular grammars A regular grammar is a PSG in which all the productions must conform to the following patterns: Either: N --> xB Or: N --> x where:
Such grammars are the most highly restricted class of PSGs.
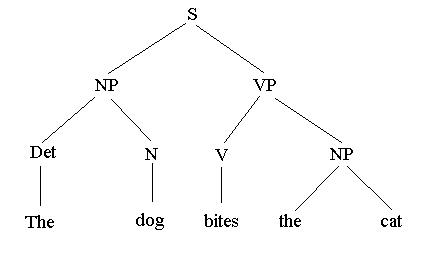
Tree diagrams In computational linguistics, context free and regular grammars are by far the most important. Unrestricted grammars are occasionally invoked, but it is rare to find any reference to context sensitive ones. The reasons for this are not directly relevant here; suffice it to say that we can afford henceforth to ignore unrestricted and context sensitive grammars. A tree is useful as a pictorial representation of structure. As a device for representing structure, it is applicable to any situation where a hierarchy of choices is made. A derivation is a perfect example of 'a hierarchy of choices', and as such a tree is ideal as a visual representation of a derivation. To construct a derivation tree, we start with a tree containing only the root node S. For each step of the derivation, the tree is correspondingly extended. That is, every time a production is used to replace a nonterminal in the current sentential form by the string on the right hand side of the production, lines are drawn from the corresponding nonterminal in the tree to each symbol in the replacement string. At each stage in the construction of the tree, reading from left to right, the leaf nodes will be the current sentential form. As an example, let us return to the set of productions for generating English strings presented earlier. These are presented again here for convenience; note, incidentally, that they come from a context-free grammar:
We now derive a sentence, and at each step build the corresponding tree:
Practice Loops There are numerous situations where a program needs to do the same thing over and over, sometimes thousands or even millions of times. An example the the string program we looked at in the last lecture:
This program does the same thing 6 times: read from the keyboard, and store the value just read in an array. This means that the programmer has to write essentially to same commands six times. What if the string became much longer. however. What, for example, if one wanted to enter the works of Shakespeare into a computer. The programmer would have to repeat these commands millions of times, once for each letter in Shakespeare's works. This would make the program huge, take vast amounts of programming time, and drive the programmer crazy. There is an alternative, however: loops.
This does the same job as the preceding one, but is much more efficient: as the number of letters to be read grows, the earlier program has to grow as well, but the one with loops just has to loop more often, that is, change the statement for i := 1 to 6 do... to for i := 1 to 1000 do... or for i := 1 to 1000000 do... and so on.
Conditionals It is often necessary to take alternative actions depending on the current state of affairs. This is true in life and in programming. A common conversation goes something like this: 'If I'm not at the Monument by 8:00 leave without me, otherwise we'll go for a drink'. Here's a programming example:
This program requires the user to enter a string of 6 letter 'a's. But humans are sometimes awkward, and sometimes make mistakes, and sometimes both. So, to ensure that the correct input is entered, this program checks to see if the user really is doing what's required. Assignment 1. Enter and run the above programs on a computer 2. Write a program that reads 6 letters from the keyboard, but only enters them into an array if the letter is an 'a'. Then output the contents of the array to the console. Reading Phrase structure grammar
Chomsky hierarchy
|